
Table of Contents
Overview
I decided to focus on a problem that has the potential to affect all of us for this project. I am going to try and solve the issue of falling asleep at the wheel by using a live video feed to detect drowsiness.
Drowsy driving has been said to be just as dangerous as drunk driving. It accounts for a total of 100000 crashes and 6000 deaths making up 7% of all crashes every year. It is definitely a prevalent problem and one that can be subsided. In order to accomplish this in real-time, the computations need to be fast. When drowsiness is detected, an alarm would sound to wake the driver up, so the computations will also need to be accurate or else there will be a lot of false alarms.
Face Detection
Computations can be run on images by using the values of each pixel. Images are just a large matrix with sets of three numbers. Each number is the value of how strong red, blue, or green is in that pixel. The first step to determining drowsiness is to take These pixel colors and detect a face from patterns in the pixels.
I detected faces in the image using something called the Histogram of Oriented Gradients (HOG). The histogram of oriented gradients is going to take the color values of each pixel and the pixels surrounding it ang give it a magnitude and direction. If there is a large difference in color between the pixel and surrounding pixel, it will be given a large magnitude. The angle of direction is going to area with the greatest difference in color. This is done in blocks on the image to determine features.
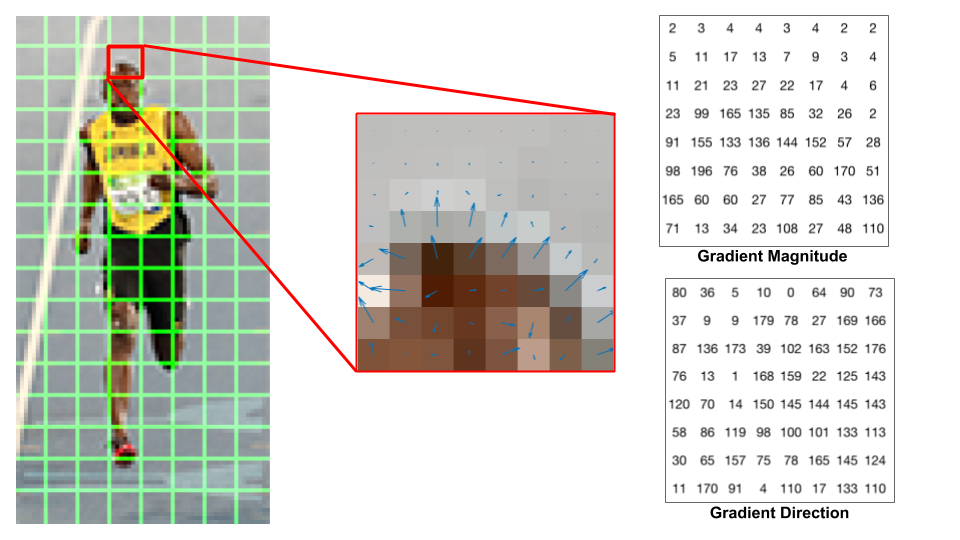
Once the magnitudes and directions are made for each pixel in the the patches, a histogram is created binning the pixels by angle. This would look something like below:
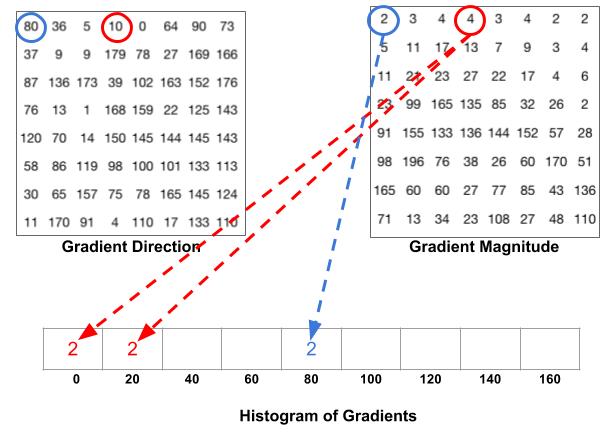
Then the histogram for a single patch would end up looking like this.
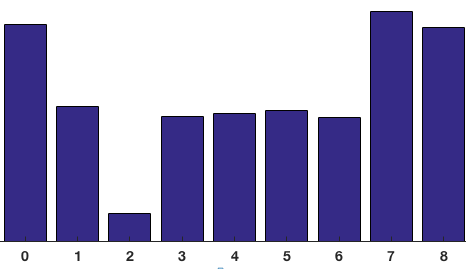
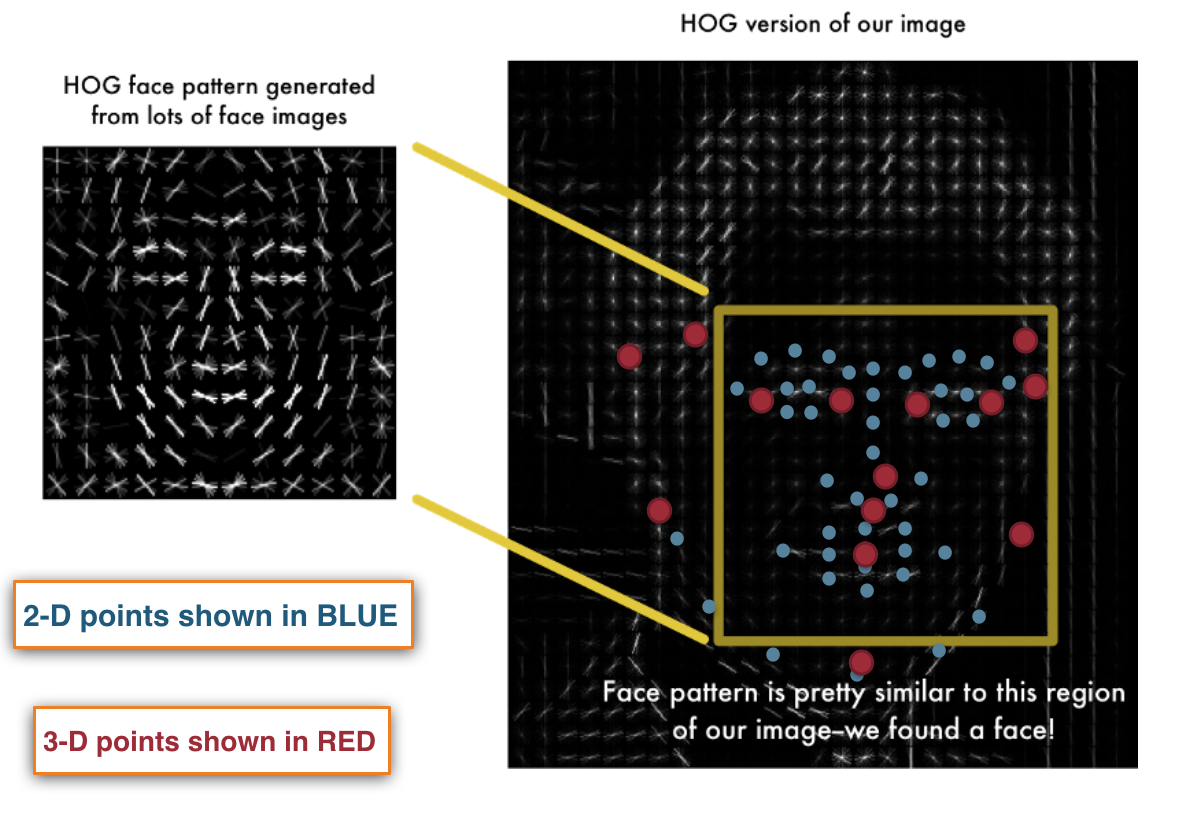
Then these histograms are input into the SVM algorithm which determines if a facial feature is found or not. This is what allows the computer to recognize the facial features of an image. The face detection package dlib uses this HOG method to detect faces and works well in real time.
Once a face is detected, two dimensional points can be mapped to the facial features for any extraction or analysis. I do two things using these points in order to determine if a driver is falling asleep. I extract the eye regions and run those images through a neural network. I also map 3-D estimated points using the 2-D points in order to use an algorithm called Perspective N Point (PNP) to determine the head tilt of the driver. An example of the face detection with points mapped to the face is shown below:
Neural Network
The neural network that I used to determine if th eyes were open or closed was kept simple to allow for fast calculations that could be done in real time. Neural networks are typically very data hungry which was concerning at first because face images are not the easiest datasets to come across. The dataset I used had approximately 3,000 pictures of faces labeled open and closed and can be found here. I extracted the eyes from these images just the same as I would on live frames using HOG. Since there is not too much variation in eye images, the network actually performed fine using just this small amount of data.
The model I used was just three convolutional layers as well as max pooling and dropout to help with overfitting. Keras makes it very easy to create these networks. It was constructed with the short snippet of code below:
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(img_channels, img_rows, img_cols)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (2,2), padding= 'same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (2,2), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
#Fully connected layer
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
#Output Layer
model.add(Dense(1))
model.add(Activation('sigmoid'))
# train with Adam
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001), metrics=['accuracy'])
The Adam optimizer is slightly more robust than classic stochastic gradient decent and it also works faster. While SGD uses a single learning rate, Adam calculates an exponential moving average of the gradient and the squared gradient. Overall, the network performed well as I was able to achieve a 95% accuracy rate to determine if an eye is open or closed.
Putting this to use in the live video stream, I count every frame that the eyes are detected as closed and once the counter hits a certain threshold, an alarm will sound to wake up the driver. This threshold will depend on the fps of the camera as well as the tilt of the drivers head.
Head Tilt
Calculating head tilt involves using a method called Perspective-n-Point (PNP) typically used in computer vision applications. This algorithm is used to find the pose of an object in an image when the locations of n 3-D points are known as well as corresponding 2-D projections. This is the reason that I mapped the 3-D estimated points to the image.
Determining head orientation is entirely dependent on movement about some determined axes. There are two types of movement that can occur:
-
Translation: Movement from the current 3D location (X, Y, Z), to a new 3D location (X’, Y’, Z’). Translation has three degrees of freedom.
-
Rotation: Staying in the same 3D location, you can rotate around the current (X, Y, Z) axes. Rotation will also have three degrees of freedom. Commonly known as roll, pitch, and yaw.
Estimating the orientation of a face would mean having to find the numbers for each of these degrees of freedom. There have been a couple different discoveries of ways to solve the perspective problem and they are all fairly complicated. OpenCV has a solvePNP function that makes face orientation easy to determine with the 3D and 2D points that I mapped. SolvePNP uses some methods called Direct Linear Transform and Levenberg-Marquardt Optimization in order to transform points on the world coordinates (the points that I mapped to the face) onto 3D points in camera coordinates which can then be projected onto the image plane. These three coordinate systems can be seen below:
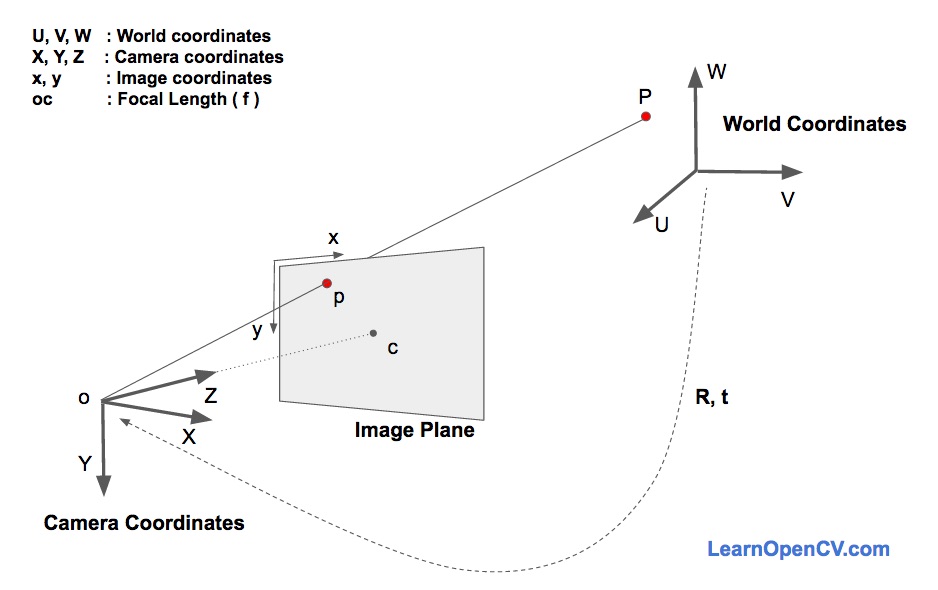
The dotted line is showing that the points in the world coordinates are being transformed onto the camera coordinates, which are then projected to the image plane (c). These methods can get quite complicated but if you are interested you can find a paper here that compares some pose estimation methods.
Intuitively, if a drivers head is tilted AND their eyes are closed, that is not a good sign. My wake up alarm is all based on timing, so if their head is tilted and eyes are closed, I half the threshold that will set the alarm off. I set the alarm to go off between 2-3 seconds of closed eyes so around 1 second if the head is tilted as well. If these seem like short amounts of time, imaging how often you actually close your eyes for three seconds while driving.
Final Product
The final product works fairly well. I ran it on an example video of a driver falling asleep but it works just as well in real time. I plan to make a web app once I get a chance so you can see how it works just using a computer camera.
I overlayed a couple things on the video so you can see what the computer is using to perform calculations. The red dots are the estimated 3D layers that were used to find the orientation axes. These axes are the small lines in the middle of the face. The red line that is pointing outward is used to find tilt. The boxes are the extracted eye regions for the neural network. The drivers head actually falls behind a mirror ornament and the face detector starts to have trouble with detection. However my model successfully anticipated sleep and sounded the alarm before his head fell. The siren is not him getting pulled over, thats the sound I thought would be most effective to wake up a driver.
Limitations
Watching the video, there are obviously some limitations to the model. The first being the face detector. This shouldn’t be a problem in real applications as the camera would be centered so the drivers face would not go out of frame. There is only really a problem when an eye is covered as they seem to be the biggest features in detecting a face. I tried the face detector while covering my mouth and it still knew my face was there.
The other problem is image quality and nighttime. A semi-decent camera will need to be used to really be effective. A night vision camera is also very necessary as the most likely time to fall asleep while driving is at night. Sunglasses are also an issue, the model will have to act solely on face tilt if sunglasses are being used.
The files I created for this project can be found here.